Add variable robust constraints
Source:R/add_variable_robust_constraints.R
add_variable_robust_constraints.RdAdd robust constraints to a conservation problem to allow the solution's level of robustness to uncertainty to differ across feature groups. For example, this function may be especially useful when it is important to ensure that a prioritization is highly robust to uncertainty in the spatial distribution of threatened species, and only moderately robust to uncertainty in the spatial distribution of widespread species.
Arguments
- x
prioritizr::problem()object.- data
tibble::tibble()data frame containing information on the feature groups and confidence level associated with each group. Defaults to 1, corresponding to a maximally robust solution.
Value
An updated prioritizr::problem() object with the constraint added
to it.
Details
The robust constraints are used to generate solutions that are robust to
uncertainty. In particular, conf_level controls how
important it is for a solution to be robust to uncertainty.
To help explain how these constraints operate, we will consider
the minimum set formulation of the reserve selection problem
(per prioritizr::add_min_set_objective().
If conf_level = 1, then the solution must be maximally robust to
uncertainty and this means that the solution must meet all of the targets
for the features associated with each feature group.
Although such a solution would be highly robust to uncertainty,
it may not be especially useful because this it might have
especially high costs (in other words, setting a high conf_level
may result in a solution with a poor objective value).
By lowering conf_level, this means that the solution must only meet
certain percentage of the targets associated with each feature group.
For example, if conf_level = 0.95, then the solution must meet, at least,
95% of the targets for the features associated with each feature group.
Alternatively, if conf_level = 0.5, then the solution must meet, at least,
half of the targets for the features associated with each feature group.
Finally, if conf_level = 0, then the solution does not need
to meet any of the targets for the features associated with each
feature group. As such, it is not recommended to use conf_level = 0.
Data format
The data argument must be a tibble::tibble() data frame that has
information on the feature groups and their confidence levels.
Here, each row corresponds to a different feature group and
columns contain information about the groups.
In particular, data must have the following columns.
- features
A
listcolumn with the names of the features that belong to each group. In particular, if a particular set of features should belong to the same group, then they should be stored in the same element of this column.- conf_level
A
numericcolumn with values that describe the confidence level associated with each feature group (ranging between 0 and 1). See the Details section for information onconf_levelvalues.- target_trans
A
charactercolumn with values that specify the method for transforming and standardizing target thresholds for each feature group. Available options include computing the ("mean") average, ("min") minimum, or ("max") maximum target threshold for each feature group. Additionally, ("none") can be specified to ensure that the target thresholds considered during optimization are based on exactly the same values as specified when building the problem—even though different features in the same group may have different targets. This column is option and if not provided then the target values will be transformed based on the average value for each feature group (similar to"mean") and a message indicating this behavior is displayed.
Data requirements
The robust constraints require that you have multiple alternative
realizations for each biodiversity element of interest (e.g.,
species, ecosystems, ecosystem services). For example, we might have 5
species of interest. By applying different spatial modeling techniques,
we might have 10 different models for each of the 5 different species
We can use these models to generate 10 alternative realizations
for each of the 5 species (yielding 50 alternative realizations in total).
To use these data, we would input these 50 alternative realizations
as 50 features when initializing a conservation planning problem
(i.e., prioritizr::problem()) and then use this function to specify which
of the of the features correspond to the same species (based on the feature
groupings parameter).
See also
Other functions for adding robust constraints:
add_constant_robust_constraints()
Examples
# Load packages
library(prioritizr)
library(terra)
library(tibble)
# Get planning unit data
pu <- get_sim_pu_raster()
# Get feature data
features <- get_sim_features()
# Define the feature group data
# Here, we will assign the first 2 features to the group A, and the
# remaining features to the group B
groups <- c(rep("A", 2), rep("B", nlyr(features) - 2))
# Next, we will use this information to create a data frame containing
# the feature groups and specifying a confidence level of 0.95 for group A,
# and a confidence level of 0.5 for group B
constraint_data <- tibble(
features = split(names(features), groups),
conf_level = c(0.95, 0.5)
)
# Display constraint data
print(constraint_data)
#> # A tibble: 2 × 2
#> features conf_level
#> <named list> <dbl>
#> 1 <chr [2]> 0.95
#> 2 <chr [3]> 0.5
# Build problem
p <-
problem(pu, features) |>
add_robust_min_set_objective() |>
add_variable_robust_constraints(data = constraint_data) |>
add_relative_targets(0.1) |>
add_binary_decisions() |>
add_default_solver(verbose = FALSE)
# Solve the problem
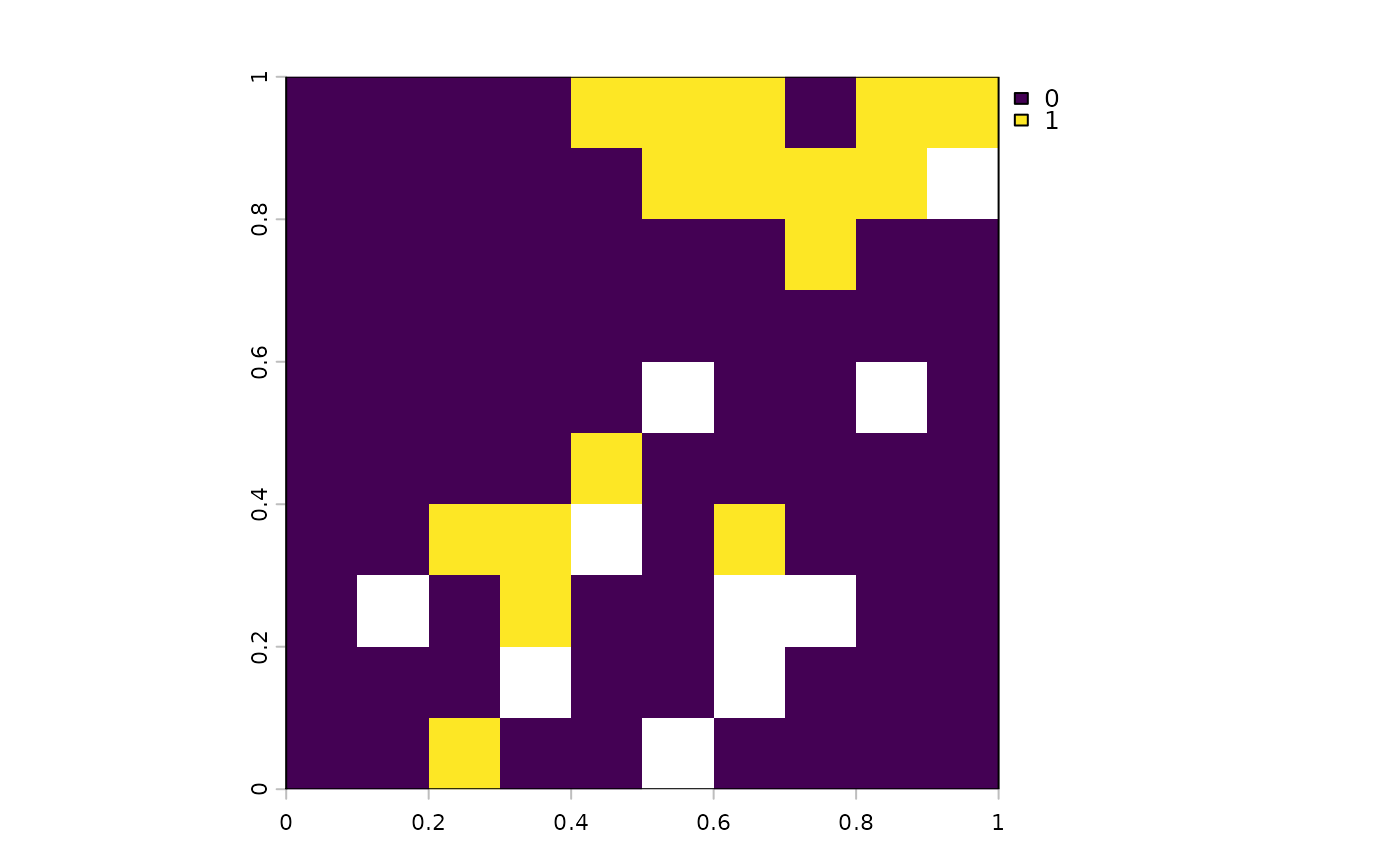
soln <- solve(p)
#> ℹ The targets for these groups are transformed based on the `mean()` target
#> value.
# Plot the solution
plot(soln)